Copyright 2021-2022 Lawrence Livermore National Security, LLC and other MuyGPyS Project Developers. See the top-level COPYRIGHT file for details.
SPDX-License-Identifier: MIT
One-Line Regression Workflow¶
This notebook walks through the same regression workflow as the univariate regression tutorial.
This workflow differs from the tutorial by making use of a high-level API that automates all of the steps contained therein. MuyGPyS.examples automates a small number of such workflows. While it is recommended to stick to the lower-level API, the supported high-level APIs are useful for the simple applications that they support.
[1]:
import matplotlib.pyplot as plt
import numpy as np
# This is necessary if JAX is installed as the benchmark GP is not designed with JAX in mind.
from MuyGPyS import config
if config.muygpys_jax_enabled is True:
config.update("muygpys_jax_enabled", False)
from MuyGPyS._test.gp import benchmark_sample, benchmark_sample_full, BenchmarkGP
We will set a random seed here for consistency when building docs. In practice we would not fix a seed.
[2]:
np.random.seed(0)
We perform the same operations to sample a curve from a conventional GP as described in the tutorial notebook.
[3]:
lb = -10.0
ub = 10.0
data_count = 5001
train_step = 10
x = np.linspace(lb, ub, data_count).reshape(data_count, 1)
test_features = x[np.mod(np.arange(data_count), train_step) != 0, :]
train_features = x[::train_step, :]
test_count, _ = test_features.shape
train_count, _ = train_features.shape
[4]:
nugget_var = 1e-14
fixed_length_scale = 1.0
benchmark_kwargs = {
"kern": "matern",
"metric": "l2",
"eps": {"val": nugget_var},
"nu": {"val": 2.0},
"length_scale": {"val": fixed_length_scale},
}
gp = BenchmarkGP(**benchmark_kwargs)
[5]:
y = benchmark_sample(gp, x)
[6]:
test_responses = y[np.mod(np.arange(data_count), train_step) != 0, :]
measurement_eps = 1e-5
train_responses = y[::train_step, :] + np.random.normal(0, measurement_eps, size=(train_count,1))
[7]:
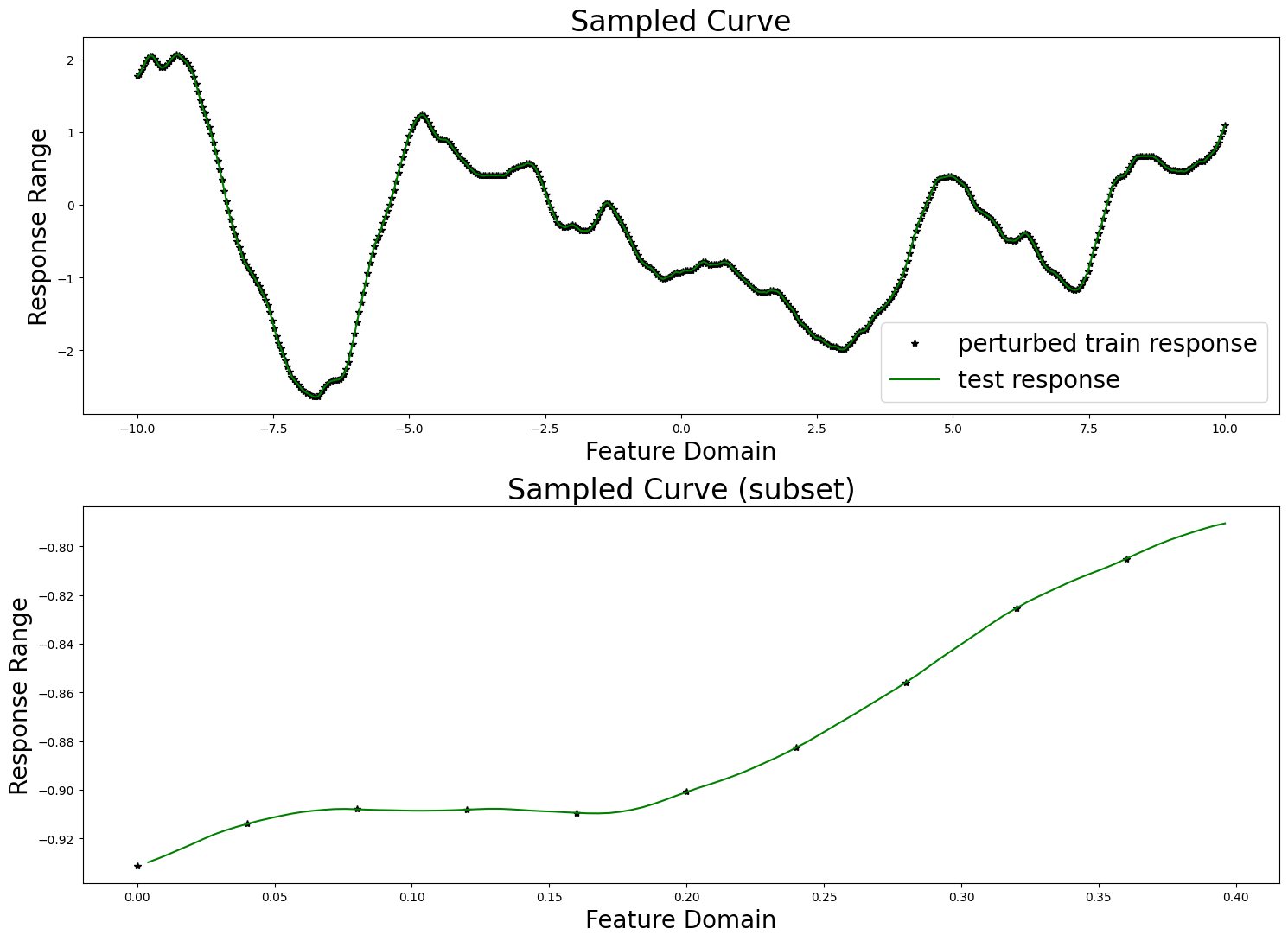
fig, axes = plt.subplots(2, 1, figsize=(15, 11))
axes[0].set_title("Sampled Curve", fontsize=24)
axes[0].set_xlabel("Feature Domain", fontsize=20)
axes[0].set_ylabel("Response Range", fontsize=20)
axes[0].plot(train_features, train_responses, "k*", label="perturbed train response")
axes[0].plot(test_features, test_responses, "g-", label="test response")
axes[0].legend(fontsize=20)
vis_subset_size = 10
mid = int(train_count / 2)
axes[1].set_title("Sampled Curve (subset)", fontsize=24)
axes[1].set_xlabel("Feature Domain", fontsize=20)
axes[1].set_ylabel("Response Range", fontsize=20)
axes[1].plot(
train_features[mid:mid + vis_subset_size],
train_responses[mid:mid + vis_subset_size],
"k*", label="perturbed train response"
)
axes[1].plot(
test_features[mid * (train_step - 1):mid * (train_step - 1) + (vis_subset_size * (train_step - 1))],
test_responses[mid * (train_step - 1):mid * (train_step - 1) + (vis_subset_size * (train_step - 1))],
"g-", label="test response"
)
plt.tight_layout()
plt.show()
We now set our nearest neighbor index and kernel parameters.
[8]:
nn_kwargs = {"nn_method": "exact", "algorithm": "ball_tree"}
k_kwargs = {
"kern": "matern",
"metric": "l2",
"eps": {"val": measurement_eps},
"nu": {"val": "log_sample", "bounds": (0.1, 5.0)},
"length_scale": {"val": fixed_length_scale},
}
opt_kwargs = {"random_state": 1, "init_points": 5, "n_iter": 20}
Finally, we run do_regress(). This function entirely instruments a simple regression workflow, with several tunable options. Most of the keyword arguments in this example are specified at their default values, so in practice this call need not be so verbose.
In particular, variance_mode and return_distances affect the number of returns. If variance_mode is None, then no variances variable will be returned. This is the default behavior. If return_distances is False, then no crosswise_dists or pairwise_dists tensors will be returned. This is also the default behavior.
The kwarg opt_method indicates which optimization method to use. In this example, we have used "bayesian", which will use the corresponding kwargs given by opt_kwargs. The other currently supported option, "scipy", expects no additional kwargs and so the user can safely omit opt_kwargs.
[9]:
from MuyGPyS.examples.regress import do_regress
muygps, nbrs_lookup, predictions, variances, crosswise_dists, pairwise_dists = do_regress(
test_features,
train_features,
train_responses,
nn_count=30,
batch_count=train_count,
loss_method="mse",
obj_method="loo_crossval",
opt_method="bayesian",
sigma_method="analytic",
variance_mode="diagonal",
k_kwargs=k_kwargs,
nn_kwargs=nn_kwargs,
opt_kwargs=opt_kwargs,
verbose=True,
apply_sigma_sq=True,
return_distances=True,
)
parameters to be optimized: ['nu']
bounds: [[0.1 5. ]]
initial x0: [0.49355858]
| iter | target | nu |
-------------------------------------
| 1 | -6.797e-0 | 0.4936 |
| 2 | -1.027e-0 | 2.143 |
| 3 | -8.11e-05 | 3.63 |
| 4 | -0.004408 | 0.1006 |
| 5 | -7.124e-0 | 1.581 |
| 6 | -1.826e-0 | 0.8191 |
| 7 | -3.023e-0 | 0.6683 |
| 8 | -2.004e-0 | 2.616 |
| 9 | -7.106e-0 | 1.611 |
| 10 | -7.109e-0 | 1.604 |
| 11 | -0.000157 | 4.303 |
| 12 | -0.000242 | 5.0 |
| 13 | -4.259e-0 | 3.122 |
| 14 | -9.146e-0 | 1.169 |
| 15 | -0.000116 | 3.964 |
| 16 | -0.000200 | 4.654 |
| 17 | -2.948e-0 | 2.869 |
| 18 | -5.975e-0 | 3.378 |
| 19 | -1.4e-05 | 2.372 |
| 20 | -3.023e-0 | 0.6682 |
| 21 | -7.951e-0 | 1.911 |
| 22 | -1.184e-0 | 1.001 |
| 23 | -7.761e-0 | 1.351 |
| 24 | -9.814e-0 | 3.798 |
| 25 | -0.000179 | 4.477 |
| 26 | -0.000223 | 4.838 |
=====================================
Optimized sigma_sq values [0.26936803]
NN lookup creation time: 0.0004490530000111903s
batch sampling time: 0.024374695000005886s
tensor creation time: 0.006403702999705274s
hyper opt time: 12.035862388000169s
sigma_sq opt time: 0.3447394169998006s
prediction time breakdown:
nn time:0.023424527999850397s
agree time:7.470002856280189e-07s
pred time:2.978775139999925s
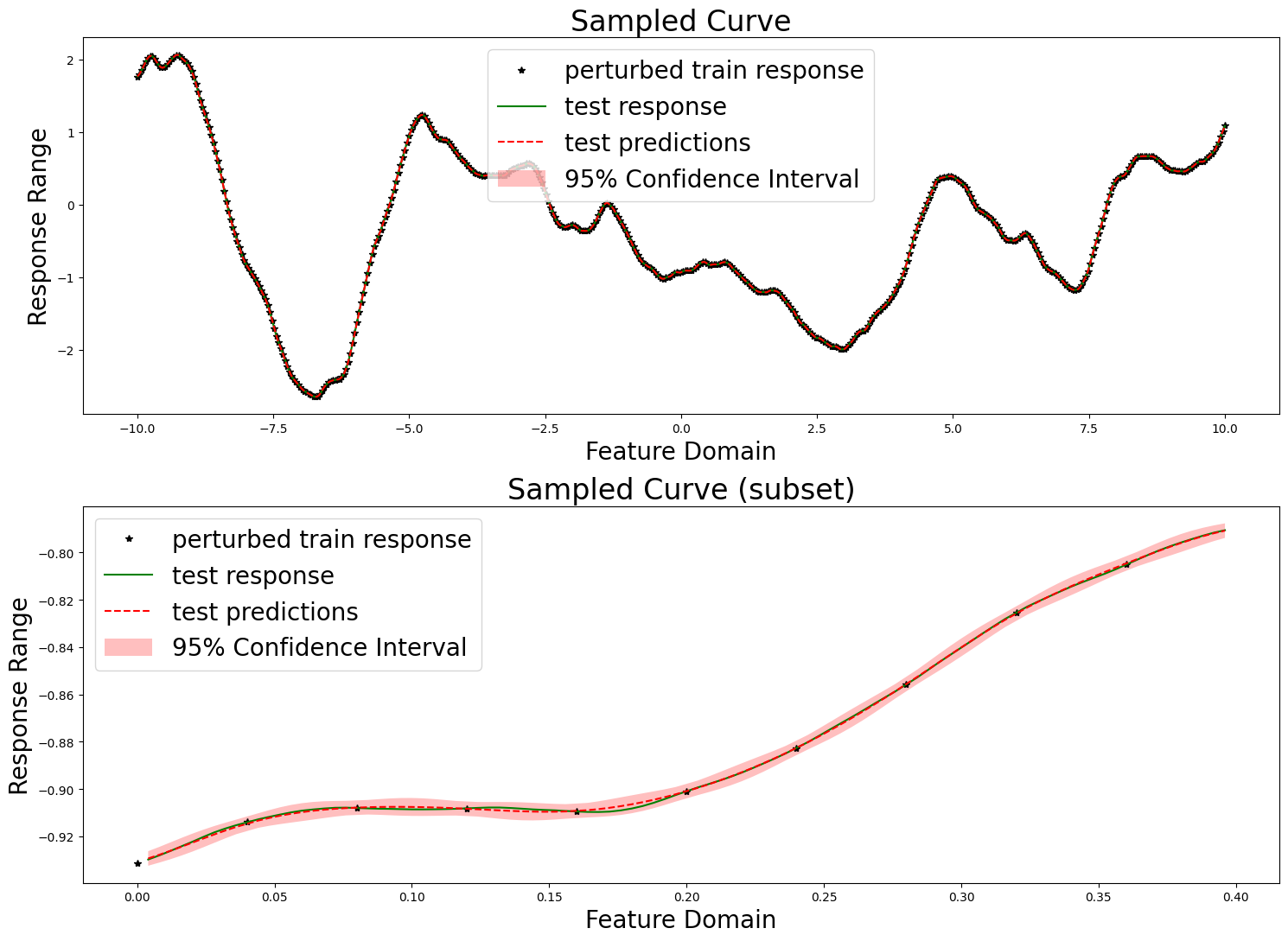
We here evaluate our prediction performance in the same manner as in the tutorial. We report the RMSE, mean diagonal posterior variance, the mean 95% confidence interval size, and the coverage, which ideally should be near 95%.
[10]:
from MuyGPyS.optimize.loss import mse_fn
confidence_intervals = np.sqrt(variances) * 1.96
coverage = (
np.count_nonzero(
np.abs(test_responses - predictions)
< confidence_intervals.reshape(test_count, 1)
)
/ test_count
)
print(f"RMSE: {np.sqrt(mse_fn(predictions, test_responses))}")
print(f"mean diagonal variance: {np.mean(variances)}")
print(f"mean confidence interval size: {np.mean(confidence_intervals * 2)}")
print(f"coverage: {coverage}")
RMSE: 0.0006262325896110677
mean diagonal variance: 3.1353185876109543e-06
mean confidence interval size: 0.006921680167052393
coverage: 1.0
We also produce the same plots.
[11]:
fig, axes = plt.subplots(2, 1, figsize=(15, 11))
axes[0].set_title("Sampled Curve", fontsize=24)
axes[0].set_xlabel("Feature Domain", fontsize=20)
axes[0].set_ylabel("Response Range", fontsize=20)
axes[0].plot(train_features, train_responses, "k*", label="perturbed train response")
axes[0].plot(test_features, test_responses, "g-", label="test response")
axes[0].plot(test_features, predictions, "r--", label="test predictions")
axes[0].fill_between(
test_features[:, 0],
(predictions[:, 0] - confidence_intervals),
(predictions[:, 0] + confidence_intervals),
facecolor="red",
alpha=0.25,
label="95% Confidence Interval",
)
axes[0].legend(fontsize=20)
axes[1].set_title("Sampled Curve (subset)", fontsize=24)
axes[1].set_xlabel("Feature Domain", fontsize=20)
axes[1].set_ylabel("Response Range", fontsize=20)
axes[1].plot(
train_features[mid:mid + vis_subset_size],
train_responses[mid:mid + vis_subset_size],
"k*", label="perturbed train response"
)
axes[1].plot(
test_features[mid * (train_step - 1):mid * (train_step - 1) + (vis_subset_size * (train_step - 1))],
test_responses[mid * (train_step - 1):mid * (train_step - 1) + (vis_subset_size * (train_step - 1))],
"g-", label="test response"
)
axes[1].plot(
test_features[mid * (train_step - 1):mid * (train_step - 1) + (vis_subset_size * (train_step - 1))],
predictions[mid * (train_step - 1):mid * (train_step - 1) + (vis_subset_size * (train_step - 1))],
"r--", label="test predictions")
axes[1].fill_between(
test_features[mid * (train_step - 1):mid * (train_step - 1) + (vis_subset_size * (train_step - 1))][:, 0],
(predictions[:, 0] - confidence_intervals)[mid * (train_step - 1):mid * (train_step - 1) + (vis_subset_size * (train_step - 1))],
(predictions[:, 0] + confidence_intervals)[mid * (train_step - 1):mid * (train_step - 1) + (vis_subset_size * (train_step - 1))],
facecolor="red",
alpha=0.25,
label="95% Confidence Interval",
)
axes[1].legend(fontsize=20)
plt.tight_layout()
plt.show()
[ ]: